


Este é o primeiro post da série que pretendo escrever sobre criação de pipeline de dados com o Kubernetes. Para iniciar, encontrei um artigo muito bom em inglês e resolvi traduzir alguns pontos interessantes sobre a utilização do Spark no Kubernetes.
O post original é este aqui.
Introdução
Apache Spark é um framework open-source para computação distribuída. Em poucas linhas de código (Scala, Python, SQL ou R) cientista de dados ou engenheiros conseguem criar aplicações que processam grandes volumes de dados em um cluster.
Porém, o Spark por si só não gerencia esse cluster. É necessário ter um gerenciador de cluster(muitas vezes também é chamado de scheduler). Os principais gerenciadores de clusters são:
Standalone: gerenciador simples com algumas features limitadas.
Apache Mesos: gerenciador open source para processos de big data(não apenas Spark) mas está desuso nos últimos anos.
Hadoop YARN: gerenciador baseado em JVM lançado em 2012 e é o mais comum utilizado hoje
Kubernetes: Spark roda nativamente no Kubernetes desde o Spark v2.3(2018). Esse modo vem ganhando tração rapidamente bem como suporte de algumas empresas ( Google, Palantir, Red Hat, Bloomberg, Lyft).
Na data da criação do artigo (junho de 2020) o suporte ainda estava marcado como experimental
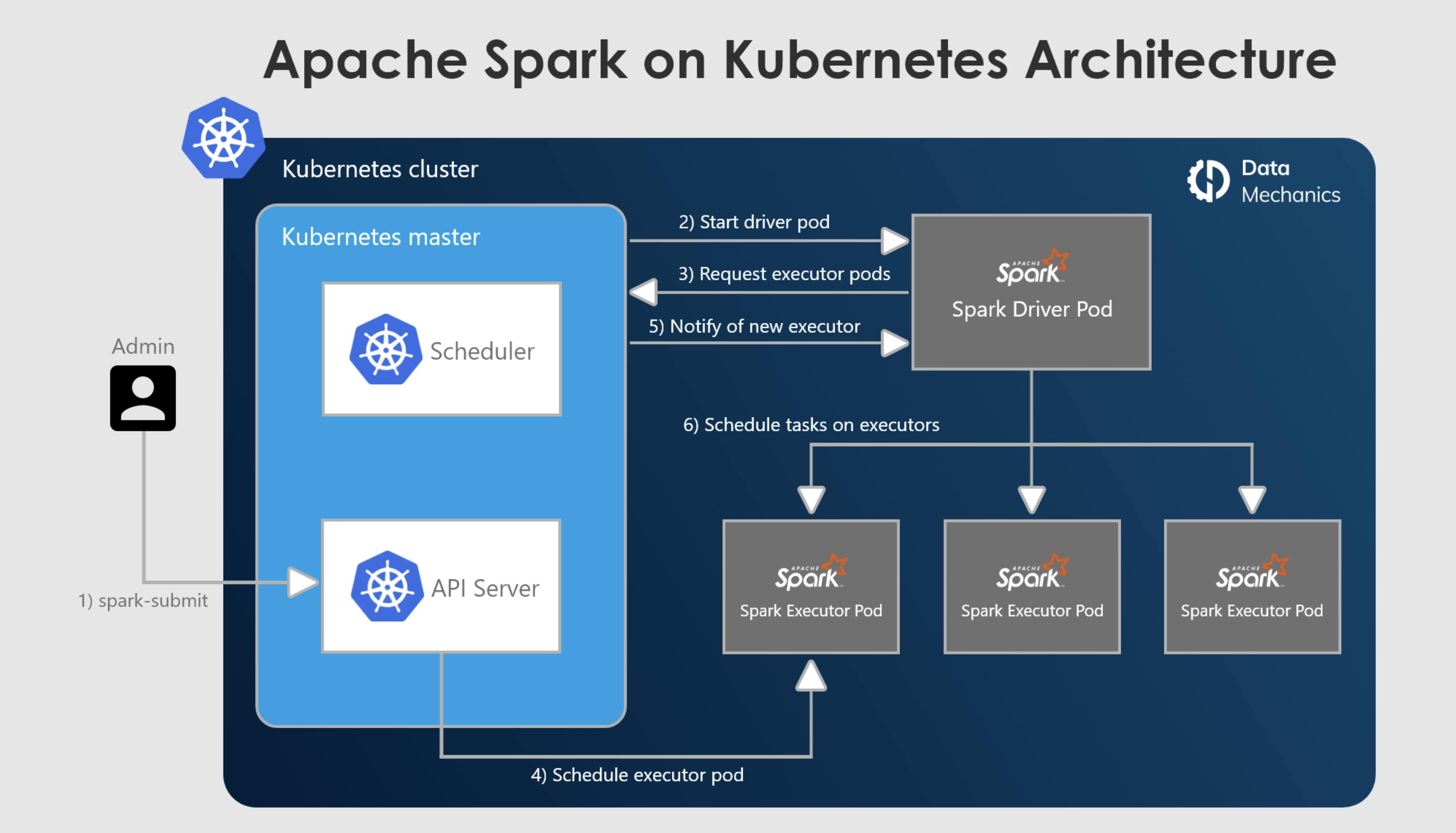
A execução de jobs Spark pode ser feita através do spark-submit ou então utilizando o spark-operator (falarei sobre em um próximo post). Dessa maneira você informa todas as configurações e dependências necessárias (empacotado via imagem docker) e o Kubernetes criará os pods do driver e executors para a execução, escalando de acordo com a carga de trabalho se o dynamic allocation estiver habilitado.
Vantagens
1. Conteinerização
Essa é a principal motivação para o uso do Kubernetes. Os benefícios da utilização de containers no contexto da engenharia de software também se aplicam ao mundo big data, permitindo que a aplicação seja portátil;
A aplicação é construída uma vez com as dependências necessárias e pode executar em qualquer lugar (localmente ou em escala)
O job se torna mais confiável e com custo eficiente
Acelera o ciclo de desenvolvimento
Dentre eles, o melhor benefício é o primeiro, em que você pode construir uma imagem para cada job ou então usar uma imagem base que possui as bibliotecas necessárias e dinâmicamente utilizar em seu job.
2. Compartilhamento de recursos mais eficiente
Em outros gerenciadores de clusters (Yarn, Standalone, Mesos) se você deseja reutilizar o mesmo cluster para jobs concorrentes afim de reduzir custos, você terá que comprometer os seguintes isolamentos:
Isolamento de dependência - As aplicações terão que ter a mesma versão do Spark, Python, compartilhar bibliotecas e ambiente
Isolamento de performance - Se algum job grande começar a ser executado, os demais podem ser comprometidos
Em consequência disso, muitas plataformas (Databricks, EMR, Dataproc) recomendam utilizar clusters transitórios, que são clusters com propósito único (iniciar, executar e terminar). Porém ainda há um problema com essa abordagem que é o custo para configuração do cluster, pois a configuração do YARN na maioria dos casos leva cerca de 10 minutos.
Spark no Kubernetes permite o melhor dos dois mundos. As aplicações podem ser executadas em um único cluster do Kubernetes e cada job pode escolher qual versão do Spark é necessária, versão do Python e dependências - você tem o total controle sobre a imagem. Em cerca de 10 segundos os containers do Spark são criados.
3. Rico ecossistema de integração - agnóstico a cloud e menos preso a fornecedores
Spark no Kubernetes permite funcionalidades poderosas já existentes como controle e utilização de namespace, regras de acesso que opcionalmente podem ser integradas com algum fornecedor em nuvem com IAM.
A performance em relação ao gerenciamento de cluster Spark com Kubernetes e YARN é praticamente a mesma. Mais detalhes desse benchmark pode ser consultado aqui
Desvantagens
Utilizar o Spark no Kubernetes com confiabilidade requer tempo e conhecimento, as features existentes para o correto funcionamento podem ser um pouco complicadas de início por ter várias coisas para configurar, como;
Criar e configurar o Kubernetes com as pools de máquinas
Configurar o spark-operator e o autoscaler (opcional, porém recomendado)
Configurar um repositório de imagens e ter um processo que empacote as dependências
Configurar o Spark History Server para visualização dos jobs que foram realizados
Configurar login, monitoramento e ferramentas de segurança
Otimizar as configurações da aplicação
Habilitar instâncias spots no cluster (opcional, porém recomendado)
Construir integrações